Analyse de sentiments en temps réel
L'objectif
L'objectif de ce projet est de construire un système end-to-end d'analyse de sentiment en temps réel.
La description du projet
Pour faire ce projet, nous avions des fichiers Jupyter déjà construits avec en commentaire les consignes détaillées et des astuces. Il nous suffisait, dans chaque cellule d'écrire le code attendu.
À notre disposition, nous avions le dataset Sentiment140 qui contient 1,6 million de tweets classés positifs ou négatifs. Nous avons fait la phase de développement avec un échantillon d'entraînement de 1 million de tweets et la phase de production sur les 600 000 restants.
Ce projet s'est déroulé en plusieurs étapes :
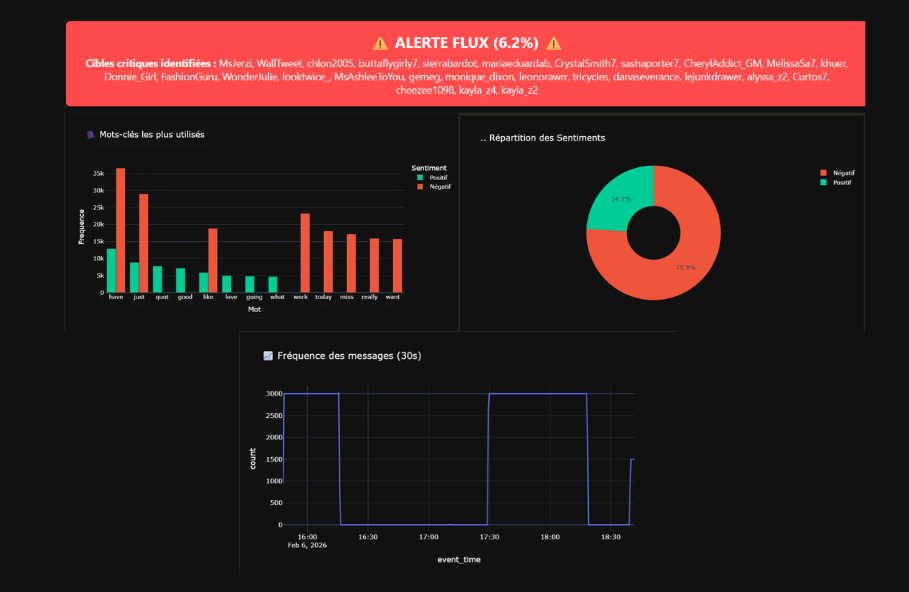
- Etape 1 : Streaming avec Pyspark : le but de cette première étape est d'analyser un flux de tweets en temps réel avec Spark Structured Streaming.
Après m'être connecté au serveur TCP, j'ai extrait les variables dont j'avais besoin et transformé le code sentiment 0 et 4 en négatif et positif. Ensuite, j'ai pu
calculé quelques indicateurs comme le nombre de tweets, le nombre de positifs et de négatifs par fenêtre de 30 secondes ou bien par utilisateur. Enfin, j'ai créé
un système d'alerte ou si le sentiement moyen est inférieur à -0,3, soit plus de 65% de négatifs, il y a une alerte.
- Etape 2 : Construire un pipeline de Machine Learning capable de predire le sentiment (positif/negatif) d'un tweet a partir de son texte. Après avoir chargé le
dataset et ajouté une colonne label pour les sentiments, j'ai nettoyé le texte le plus possible afin d'méliorer la performance du modèle crée par la suite. Pour
construire mon modèle, j'ai mis en place un pipeline (une chaîne de traitement automatique) qui enchaîne les étapes suivantes :
• La tokenisation : consiste à couper le texte pour isoler chaque mot.
• Le StopWords : permet de nettoyer le texte en supprimant les mots « vides » qui n'apportent pas de sens (comme "le", "de", "et").
• Le Bigram : permet de regrouper les mots deux par deux (par exemple, "ne pas") pour conserver le contexte que des mots isolés perdraient.
• La vectorisation : transforme les mots et les bigrammes en listes de nombres pour qu'ils soient compréhensibles par l'ordinateur.
• Le Vector Assembler : fusionne les mots seuls et les groupes de deux mots (bigrammes) en un seul bloc de données.
• L'IDF (Fréquence Documentaire Inverse) : une technique qui réduit l'importance des mots trop fréquents (comme "tweet") pour mettre en avant les mots
plus rares et plus significatifs.
• Le Normalizer : ajuste les données pour que la longueur d'un message (un tweet court ou long) n'influence pas injustement le résultat.
• La Régression Logistique : c'est le modèle final qui analyse toutes ces données pour classer automatiquement le tweet dans la bonne catégorie."
Enfin, j'ai sauvegardé le modèle sur HDFS (un système de stockage de données distribué) une fois que les résultats des metrics (les indicateurs de
performance : accuracy, F1-score, ...) n'évoluaient plus. J'ai donc estimé que c'était le meilleur modèle que je pouvais obtenir.
- Etape 3 : Construction d'un pipeline intégrant les étapes précédentes. Pour cette construction, j'ai commencé par vérifier la connexion à Kafka afin de créer un
KafkaProducer (qui envoie les données) et un KafkaConsumer (qui les reçoit). Ensuite, j'ai configuré le Spark Streaming pour lire les messages Kafka en temps
réel et y intégrer mon modèle de Machine Learning (ML). Enfin, j'ai écrit les résultats dans HDFS et sauvegardé les données pour permettre la réalisation du
dashboard (tableau de bord interactif).
- Etape 4 : Réalisation du Dashboard. A partir des résultats précedent, j'ai pu construire des indicateurs pour alimenter les différents graphiques.
L'évaluation
- Respect des consignes
- Qualité des résultats : modèle et dashboard
- Réponses apportées aux questions
Les compétences acquises
- Création d'un modèle de classification à partir de texte
- Gestion d'un flux de données en temps réel
- Construction d'un pipeline
- Réalisation d'un dashboard interractif avec des données en temps réel
Le bilan personnel
Ce projet m'a permis d'apprendre à mettre en place un pipeline complet d'analyse de sentiments en temps réel, depuis le streaming de données jusqu'au dashboard final. J'ai aussi renforcé mes compétences en traitement de texte et en Machine Learning avec PySpark, notamment sur la préparation des données et l'amélioration d'un modèle de classification. Enfin, ce projet m'a permis de mieux comprendre l'importance de connecter plusieurs outils (Kafka, Spark, HDFS) pour construire une solution robuste et exploitable.
télécharger le projet